















































































































































Jacob Bickford is a Web Archiving Assistant at The National Archives. He recently completed the Postgraduate Certificate in Applied Data Science at Birkbeck with support from the DPC Career Development Fund, which is funded by DPC Supporters.
At the end of August, I completed the Postgraduate Certificate in Applied Data Science at Birkbeck, University of London. The course came out of the Computing for Cultural Heritage program, developed by the British Library, The National Archives and Birkbeck. It is an intensive course designed to provide applied programming and data science skills to graduates who do not have formal qualifications in computer science.
As one of The National Archives’ Bridging the Digital Gap trainees and in my subsequent role at the University of Westminster Archive I had been experimenting with using simple Python scripts to automate digital preservation workflows and the course was an ideal opportunity to build on this foundation and learn more. The course consists of two taught modules and a work-based final project. The first module introduced us to fundamental concepts in computer science using Python and SQL, while the second provided a – sometimes very intensive! – introduction to data science, machine learning and some of the mathematical principles that underpin them. For both modules we would have a lecture outlining the key concepts, followed by an online ‘lab’ in which we worked through programming and data science exercises. While I’ve worked in IT and had some Python experience, I’ve only formally studied humanities subjects since leaving school and the second module in particular was a challenging but rewarding experience. Armed with the skills we had gained through the taught modules; we were then assigned a supervisor and set to work to develop a final project consisting of a piece of software that addressed a computing or data science requirement in our workplace.
One of the data science techniques that we had been shown was Natural Language Processing (NLP), essentially using computers to try to interpret and analyse large texts. I had previously touched on this topic by attending one of James Baker’s brilliant workshops on Computational Analysis of Catalogue Data and I knew that Chris Day at The National Archives had done similar work as part of the Computing for Cultural Heritage pilot program. Rather than work with catalogue data, however, I thought that Westminster’s digitised Polytechnic Magazines would be a great collection to use to try out some NLP techniques. The Polytechnic Magazine was the in-house magazine of the Regent Street Polytechnic, one of the predecessor institutions of the University. Since 2011, a digitised run of the magazine covering the years 1879 to 1960 has been made available by the University Archive via a dedicated website and I was able to access the digitised PDFs for my project. You can see an example of one of the digitised magazines below. At Westminster we had been using the DPC’s Rapid Assessment Model to evaluate our digital preservation maturity and an area we had identified for further work was improving the level of digital access to our collections. Through my work on web archiving I was aware of the Archives Unleashed and GLAM Workbench projects that use Jupyter notebooks to give computational access to this sort of material and I wondered if I could do something similar with the Polytechnic Magazines.

A Polytechnic Magazine from January 1915
The first challenge was getting the PDFs into a format that was machine-readable so that I could experiment on them with some NLP techniques. The magazines had been scanned with Optical Character Recognition (OCR) as part of the original project. I initially thought I could therefore simply extract the text from the PDFs, however I found that while the character accuracy in the original OCR was good, it tended to run sentences from different paragraphs together and I was concerned that this would distort my analysis. I therefore assessed various options for re-OCRing the text, eventually settling on using Tesseract with a workflow adapted from Andrew Akhlaghi’s Programming Historian lesson combined with a simple Python script to automate the process. I then spent some time checking the accuracy of the OCR, and making some basic corrections using techniques from Jonathan Blaney, Sarah Milligan, Marty Steer and Jane Winter's excellent book Doing Digital History. At the end of this process, I was left with 1,725 plain text files, along with metadata I had created during the OCR and checking process.
For the next stage of the project, I ingested the files into a Pandas DataFrame: a way of managing data in Python in a tabular form, like a spreadsheet. The DataFrame had one row per issue of the magazine including the extracted text along with metadata like the publication date and issue number. From there, after a lot more cleaning and normalisation of the text, I was able to begin to apply some NLP techniques to the corpus. I started off by plotting some simple charts, for example counting the number of words in each issue and plotting it against the date. I was encouraged to see that these reflected what we already knew about the corpus, for example the chart below showing wordcount over time reflects the rapid decline in the length of the magazine during the Second World War.
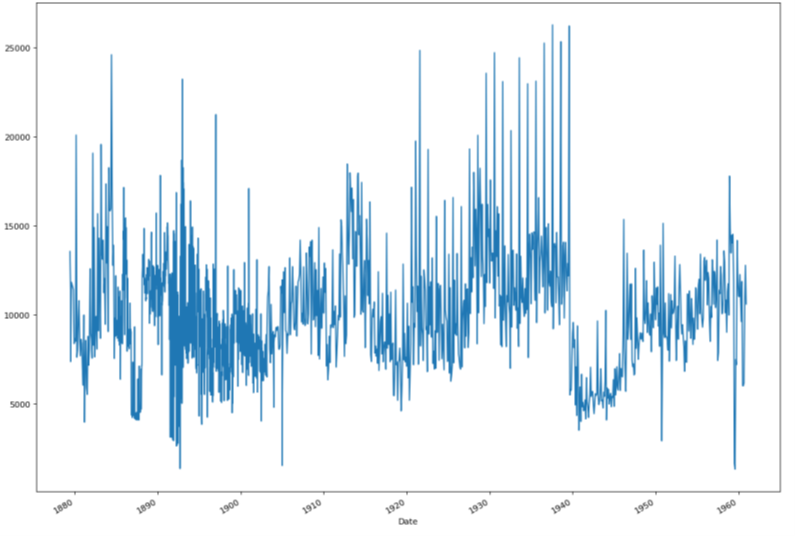
Looking at word counts over time
Using the Python library NLTK it was then possible to do a frequency analysis of the text, essentially counting the number of times each word occurred in the magazines overall, but also in each issue of the magazine individually. This made it possible to compare how often terms were used over time, for example in the chart below looking at the prevalence of terms relating to different sports societies at the Polytechnic.

Frequency chart of terms relating to sports clubs
During this experimental phase, I also tried out some topic modelling using Genism. Essentially this involves using a mathematical model to try to find clusters of related words that define topics in a corpus. As well as the work of James Baker and Chris Day mentioned above, anyone interested in topic modelling should check out Alice Zhao’s wonderfully accessible tutorials. With the form of topic modelling I used, the algorithm will identify the words in a topic and assess how relevant they are to the topic, leaving you to interpret the overall meaning of the topic. This proved trickier with some topics than others. One of the clearest topics that often seemed to occur contained terms relating to war, unsurprising given the Polytechnic’s commitment to the war effort during the First and Second World Wars. One term that seems out of place in this topic is ‘sock’ but it in fact represents a key part of the Polytechnic’s war effort, with members knitting socks that were sent to Polytechnic members serving at the front. You can see a visualisation of the ‘war’ topic for the years 1914 – 45 below. Other topics were much harder to interpret, for example containing some terms that were common in other topics such as ‘wicket’ and ‘geography’ along with more unusual words such as ‘sleep’, ‘dream’ and ‘pray’. Nevertheless, it felt like the topic modelling was a useful proof of concept and I hope it’s something other researchers will be able to experiment with and refine.
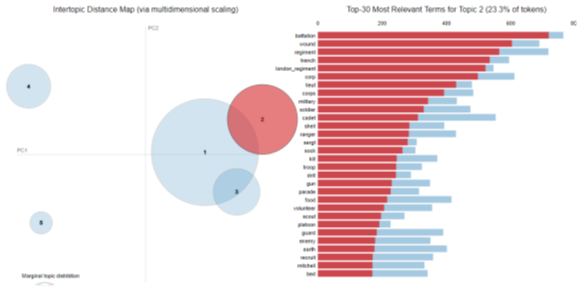
Visualisation of the 'war' topic
I wanted the project to have a few of main outputs to enable our researchers and students to continue to access the material in new ways and hopefully build on the work I’d done. With that in mind, I have made several public resources available on my project GitHub page. Firstly, if you want to try using existing text analysis applications like AntConc on the corpus, or to set up your own NLP pipeline from scratch, you can just download the corrected plain text files. Alternatively, if you are already a Python user, you can download the DataFrame as a pickled file, this has the advantage of containing the metadata such as dates as well as providing the text at various stages of pre-processing, such as tokenization and lemmatization. Finally, inspired by Archives Unleashed and GLAM Workbench, I created two public Jupyter notebooks, shared via Google Colab, which will let you do your own basic frequency analysis and topic modelling. The great thing about Colab is it will run the code directly in your browser without you having to download anything and I’ve set up the notebooks so you can just add your own parameters (for example keywords you would like to do frequency analysis of) without having to manipulate the actual code. I really hope that the public notebooks in particular will provide a useful entry point for researchers and students who are interested in approaching the material in new ways.
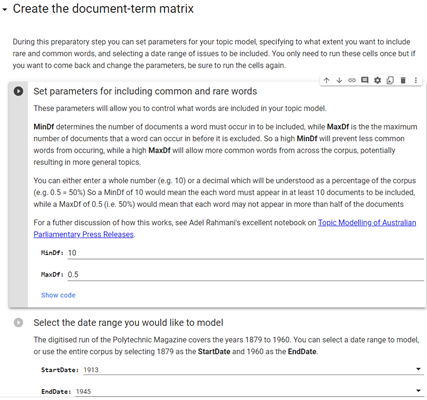
Part of the public notebook for topic modelling, showing how the user can set parameters
The course involved a lot of challenging work, but I’m so glad I did it and am very grateful to the DPC for their financial support and to my former colleagues at Westminster who supported me in many ways. I’d also like to thank the team at Birkbeck, especially my supervisor Dimitrios Airantzis. If anyone from the digital preservation and archives community is considering taking the course and would like to have an informal chat about it, feel free drop me a line on twitter @b1ninch